Как собрать семантическое ядро конкурентов по регионам через мобильные прокси: пошаговый гайд
Содержание статьи
- Введение
- Предварительная подготовка
- Базовые понятия
- Шаг 1: определяем целевые запросы и список регионов
- Шаг 2: настраиваем мобильные прокси по городам и подтверждаем гео
- Шаг 3: готовим python-окружение и структуру проекта
- Шаг 4: составляем список прямых конкурентов по каждому региону
- Шаг 5: парсим топ-50 результатов по запросам и городам (google и яндекс)
- Шаг 6: очистка, нормализация и извлечение доменов
- Шаг 7: кластеризация собранной семантики по интенту
- Шаг 8: объединяем данные и готовим аналитические срезы
- Шаг 9: анализ различий выдачи по регионам и локализации запросов
- Проверка результата
- Типичные ошибки и решения
- Дополнительные возможности
- Faq
- Заключение
Введение
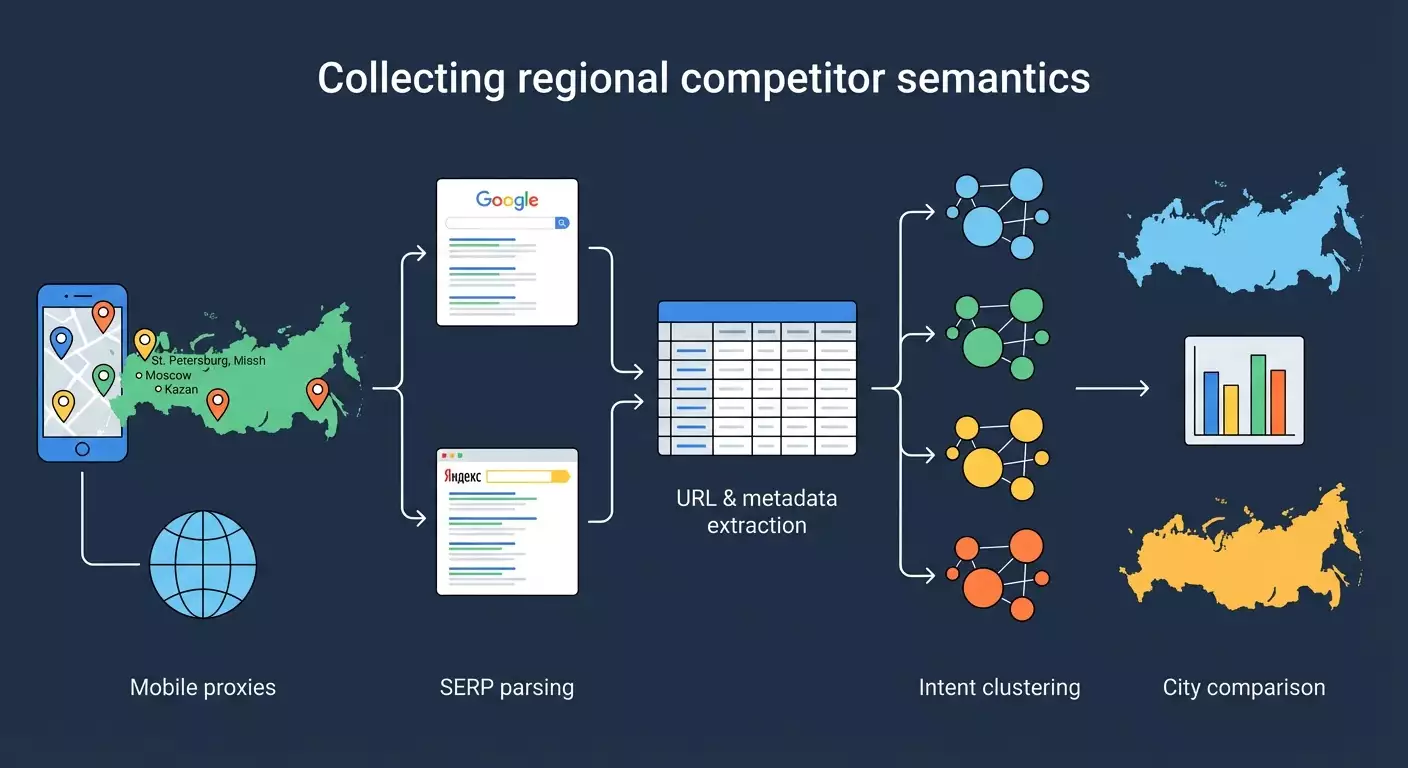
В этом пошаговом гайде вы научитесь собирать семантическое ядро конкурентов в разных регионах России, используя мобильные прокси, парсинг поисковой выдачи Google и Яндекса, а также инструменты для группировки и анализа. Мы пройдем весь путь от нуля: подготовка окружения, настройка прокси по городам, парсинг топ-50 результатов по целевым запросам, извлечение URL, title, description, позиций, кластеризация собранной семантики по интентам (информационный, коммерческий, навигационный), сравнение выдачи по регионам и подготовка практического отчета для SEO-решений.
В итоге вы получите: 1) список конкурентов по каждому городу, 2) таблицу ключевых слов, по которым конкуренты ранжируются в разных регионах, 3) метрики различий региональной выдачи и локализации запросов, 4) сгруппированные кластеры интентов для экономии бюджета и приоритизации контента, 5) повторяемый конвейер, который можно запускать ежемесячно.
Этот гайд подходит SEO-специалистам, интернет-маркетологам, аналитикам, а также всем, кто хочет понять, как устроена региональная выдача и как быстро извлечь полезные данные для принятия решений. Уровень сложности — для начинающих с элементами для продвинутых. Мы не будем требовать глубоких навыков программирования, но минимальная работа с Python пригодится.
Что нужно знать заранее: базовое понимание SEO, как формируются сниппеты, чем отличаются информационные и коммерческие запросы, как работать с CSV/Excel. Сколько времени потребуется: при готовых запросах и списке городов — 6–10 часов на первый запуск, 1–3 часа на повторные итерации.
✅ Проверка: Вы понимаете, что получите конкретный список конкурентов по городам, общую и уникальную семантику, а также сможете объяснить, какие запросы локализованы и как это использовать в региональном SEO.
Предварительная подготовка
Необходимые инструменты: 1) Учетная запись и доступ к мобильным прокси mobileproxy.space с городами РФ (Москва, Санкт-Петербург, Екатеринбург, Новосибирск, Казань и другие по вашей задаче). 2) Python 3.10+ и пакетный менеджер pip. 3) Библиотеки Python: requests, beautifulsoup4, lxml, pandas, urllib3, tldextract (для извлечения доменов). 4) Текстовый редактор (VS Code или аналог). 5) Табличный редактор (Excel, Google Таблицы или LibreOffice Calc). 6) Key Collector на Windows для группировки и кластеризации запросов. 7) Терминал или командная строка. 8) Опционально: curl для быстрой проверки прокси. 9) Доступ к браузеру для проверки гео через Яндекс.Интернетометр (сайт от Яндекса для проверки IP-геолокации).
Системные требования: Windows 10/11 или macOS 12+ или Linux (Ubuntu 22.04+), 8 ГБ ОЗУ минимум, стабильный интернет 10 Мбит/с+, свободное место на диске 2–5 ГБ для данных и логов.
Что нужно установить: 1) Установите Python последней стабильной версии. 2) Установите Key Collector на Windows. 3) Создайте учетную запись на mobileproxy.space, пополните баланс и приобретите прокси по нужным городам (1 прокси на город, лучше 2–3 для распределения нагрузки). 4) Установите библиотеки: в терминале выполните: pip install requests beautifulsoup4 lxml pandas urllib3 tldextract. 5) Настройте текстовый редактор и терминал.
Создание резервных копий: создайте папку проекта с подпапками data/raw, data/clean, reports, config, logs и периодически копируйте файлы CSV в резервную папку или в облако.
⚠️ Внимание: Убедитесь, что ваши действия соответствуют законодательству и правилам сервисов. Некоторые поисковые системы ограничивают автоматизированный сбор данных. Используйте разумный лимит запросов, читайте robots.txt, соблюдайте правила и рассматривайте официальные API как предпочтительный метод.
Совет: Создайте виртуальное окружение Python (python -m venv .venv и затем активируйте) и закрепите зависимости в requirements.txt, чтобы легко переносить проект.
✅ Проверка: В терминале команды python --version и pip --version работают, библиотеки установлены без ошибок, у вас есть доступ к хотя бы одному прокси для Москвы и вы можете открыть Яндекс.Интернетометр в браузере.
Базовые понятия
Ключевые термины простым языком: 1) Семантическое ядро — перечень поисковых запросов, по которым вы хотите ранжироваться или анализируете конкурентов. 2) Региональная выдача — результаты поиска, сформированные с учетом местоположения пользователя (город, регион). 3) Мобильные прокси — прокси-сервера на базе мобильных операторов, которые позволяют имитировать трафик с реальных мобильных IP-адресов и, что важнее для нашего кейса, выбирать город. 4) Парсинг SERP — извлечение данных из страницы результатов поиска (URL, title, snippet, позиция). 5) Интент — предполагаемая цель пользователя: информационный (узнать), коммерческий (купить/заказать), навигационный (найти конкретный сайт). 6) Топ-50 — первые 50 органических результатов, без рекламы.
Основные принципы работы: мы отправляем запрос в поисковую систему, указываем прокси, чтобы зафиксировать гео, получаем HTML-страницу, извлекаем нужные элементы, сохраняем их в таблицу. Повторяем для каждого города и каждого запроса. Далее группируем и анализируем.
Что важно понимать: 1) В разных городах набор доменов и страниц в топе может отличаться. 2) Локализованные запросы часто содержат названия городов или подразумевают локальный интент (например, доставка, рядом, адрес). 3) Слишком частые запросы без пауз могут вызвать капчу или блокировку. 4) Правильная проверка гео — критична. 5) Часть результатов может быть персонализирована; используйте чистые сессии, без авторизации.
Совет: При анализе ориентируйтесь не только на ключевые слова, но и на домены конкурентов и тип контента, чтобы выбирать правильную стратегию (локальные страницы, каталоги, статьи, лендинги).
Шаг 1: Определяем целевые запросы и список регионов
Цель этапа
Сформировать исходный список запросов и перечень городов, по которым будем собирать выдачу. Это база для парсинга и сравнения.
Пошаговая инструкция
- Откройте таблицу (Excel или Google Таблицы) и создайте лист Seeds.
- В колонке A перечислите базовые запросы, отражающие ваш продукт или нишу. Например: “доставка воды”, “ремонт ноутбуков”, “купить мебель” и т.д.
- В колонке B добавьте уточнения или синонимы, если они важны. Например: “питьевая вода”, “ремонт MacBook”, “шкаф купе”.
- Создайте лист Cities. В колонке A перечислите города: Москва, Санкт-Петербург, Екатеринбург, Новосибирск, Казань, Нижний Новгород, Самара, Челябинск, Омск, Ростов-на-Дону, Уфа, Красноярск и другие целевые регионы.
- Определите приоритет: выделите 10–15 ключевых городов с максимальным спросом.
- Сформируйте список целевых запросов, объединяя базовые и уточнения. Например: “доставка воды”, “доставка воды домой”, “питьевая вода доставка”, “ремонт ноутбуков”, “ремонт ноутбуков срочно”.
- Сохраните таблицу в папку data/raw как seeds_and_cities.xlsx.
Важные моменты: Не добавляйте пока названия городов в запросы, чтобы оценить локализацию без явного гео. Вы позже проверите и с гео-модификаторами.
Совет: Ограничьте список до 50–200 запросов для первого запуска, чтобы не перегружать прокси и не тратить лишнее время.
✅ Проверка: У вас есть один файл с 50–200 запросами и 10–15 городами. Запросы понятны и соответствуют бизнес-целям.
Возможные проблемы и решения: если трудно сформировать список, возьмите данные из внутренних поисковых подсказок вашего сайта, чаты с клиентами, список услуг и продуктовых категорий. Затем расширьте подсказками в поиске вручную.
Шаг 2: Настраиваем мобильные прокси по городам и подтверждаем гео
Цель этапа
Подключить мобильные прокси из mobileproxy.space для каждого города, проверить, что IP действительно соответствует нужному городу с помощью Яндекс.Интернетометра.
Пошаговая инструкция
- Зайдите в личный кабинет на mobileproxy.space. Выберите тариф с возможностью выбора города и оператора. Возьмите по крайней мере по одному прокси на каждый город из вашего списка. Оптимально — 2–3 прокси на город.
- Запишите для каждого прокси: хост, порт, логин и пароль. Например: proxy.example.host:12345, user:pass.
- Если поддерживается ротация по ссылке или API, сохраните ссылку для смены IP. Это пригодится для сброса сессий при капче.
- Создайте файл config/proxies.csv с колонками city, host, port, user, password, rotation_url (если есть) и заполните его.
- Откройте браузер, включите системный или браузерный прокси для Москвы и зайдите на сервис проверки IP и геолокации от Яндекса (Яндекс.Интернетометр). Убедитесь, что город определяется как Москва.
- Повторите проверку для Санкт-Петербурга, Екатеринбурга и других городов, меняя настройки прокси.
- Снимите прокси в браузере. В дальнейшем проверку гео будем делать программно.
⚠️ Внимание: Используйте прокси только в соответствии с условиями сервиса и законом. Цель прокси — корректно фиксировать гео и равномерно распределять нагрузку, а не обходить ограничения.
Совет: Создайте несложный тайм-аут: после смены прокси подождите 10–20 секунд перед проверкой гео, чтобы избежать «кеша» или задержки в сети.
✅ Проверка: Для каждого города вы можете включить соответствующий прокси и увидеть корректный город в Яндекс.Интернетометре.
Проблемы и решения: если город определяется неверно, смените IP через ротацию, возьмите другой оператор в том же городе или обратитесь в поддержку. Если браузер игнорирует прокси, проверьте настройки и авторизацию.
Шаг 3: Готовим Python-окружение и структуру проекта
Цель этапа
Создать стабильное окружение для парсинга и анализа: структура каталогов, зависимости, тест связи через прокси.
Пошаговая инструкция
- Создайте папку проекта, например regional-serp-competitors.
- Внутри создайте подпапки: config, data/raw, data/clean, logs, reports, scripts.
- Создайте виртуальное окружение: в терминале выполните “python -m venv .venv” и активируйте его (Windows: “.venv\Scripts\activate”, macOS/Linux: “source .venv/bin/activate”).
- Установите зависимости: “pip install requests beautifulsoup4 lxml pandas urllib3 tldextract”.
- Создайте файл config/settings.yaml. Внесите туда базовые параметры: тайм-ауты, задержки (например delay_min: 3, delay_max: 8), максимальные попытки повтора (retries: 3), user-agent.
- Создайте скрипт scripts/test_proxy_geo.py, который будет загружать страницу Яндекс.Интернетометра через один из прокси и печатать город, определенный в HTML.
- В скрипте настройте прокси как словарь формата: {"http": "http://user:pass@host:port", "https": "http://user:pass@host:port"} и сделайте запрос requests.get к странице проверки IP, затем найдите в HTML узел с городом (по тексту “Город” или аналогичному элементу).
- Запустите скрипт для нескольких городов и убедитесь, что вывод совпадает с ожидаемым.
Совет: Задайте единый User-Agent, например “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0 Safari/537.36”, и при необходимости меняйте его раз в 20–50 запросов.
✅ Проверка: Скрипт test_proxy_geo.py корректно выводит разные города при смене прокси. В логах нет постоянных тайм-аутов и ошибок авторизации.
Проблемы и решения: если requests получает 407 Proxy Authentication Required, проверьте логин и пароль, экранирование символов. Если получаете капчу, увеличьте задержку и включите ротацию IP реже и плавнее.
Шаг 4: Составляем список прямых конкурентов по каждому региону
Цель этапа
Определить домены конкурентов в каждом городе, чтобы потом отслеживать их ранжирование и собирать семантику.
Пошаговая инструкция
- Выберите 5–10 ключевых запросов из вашего списка, которые точно отражают целевую услугу или товар без гео-уточнений.
- Создайте скрипт scripts/collect_competitors.py. Для каждого города возьмите соответствующий прокси. По каждому из выбранных запросов отправьте поиск в Яндекс и Google последовательно.
- Для Яндекса используйте параметры запроса, учитывающие язык и регион. Например, добавьте lr (код региона), если вы его знаете, иначе положитесь на прокси-гео.
- Для Google задайте параметры hl=ru, gl=ru. Гео определится по IP; дополнительно можно тестировать безопасные параметры поиска.
- Извлекайте первые 20–30 органических результатов. Пропускайте рекламные блоки, сервисы и колдунщики, если они не релевантны целям.
- Нормализуйте домены с помощью tldextract. Сохраните для каждого города частотность доменов: домен, сколько раз встречается в топе, по каким запросам.
- Сформируйте таблицу data/raw/competitors_by_city.csv с колонками city, domain, engine, frequency, queries.
Важные моменты: Персональные сервисы (карты, маркетплейсы) могут быть доминирующими. Оставляйте их, если они реальны конкуренты по выдаче. Если вы B2B, фильтруйте новостные агрегаторы.
Совет: Дополнительно создайте «ручную проверку» для 1–2 запросов в каждом городе в вашем браузере под соответствующим прокси и сравните домены с результатами скрипта. Это повысит уверенность в точности парсинга.
✅ Проверка: Для каждого города есть список 10–30 доменов с указанием частотности. В топе присутствуют локальные сайты и федеральные игроки. Данные из скрипта близки к ручной проверке.
Проблемы и решения: несовпадения с ручной проверкой могут быть из-за динамики выдачи, персонализации или неправильной фильтрации рекламных блоков. Увеличьте задержки, используйте чистую сессию и дополнительные проверки.
Шаг 5: Парсим топ-50 результатов по запросам и городам (Google и Яндекс)
Цель этапа
Собрать детальную таблицу результатов: URL, title, description, позиция, поисковик, город, запрос.
Пошаговая инструкция
- Создайте скрипт scripts/serp_scraper.py. Структура: функции для запроса к Яндексу и Google, функция для парсинга HTML, сохранение строк в CSV.
- Сделайте конфиг с параметрами: количество результатов per_city_per_query_limit: 50, задержки delay_min, delay_max, максимальные повторы retries: 3, список User-Agent строк.
- Формируйте URL поиска. Пример Google: “https://www.google.com/search?q=запрос&num=50&hl=ru&gl=ru&pws=0”. Пример Яндекс: “https://yandex.ru/search/?text=запрос&lr=код_региона&numdoc=50”, если lr неизвестен, полагайтесь на IP-гео.
- Устанавливайте прокси по городу. Прокси-словарь: {"http": "http://user:pass@host:port", "https": "http://user:pass@host:port"}.
- Запрашивайте страницу с тайм-аутом 20–30 секунд. Обрабатывайте ошибки: тайм-аут, 429, 5xx. При ошибках делайте паузу 30–60 секунд и повторяйте с тем же прокси.
- Парсинг Google: найдите контейнеры результатов: блоки с тегами h3 для заголовков и ссылками, сниппеты в соседних div/span. Исключайте ссылки на кеш, картинки, видео, объявления. Если структура отличается, используйте все найденные “a” с видимым заголовком внутри блока результатов и фильтруйте по доменам.
- Парсинг Яндекс: ищите органические карточки результатов. Вытаскивайте “a” со ссылкой на результат, заголовок, подсказочный текст. Исключайте колдунщики (карты, справочник), если они не входят в анализ, иначе помечайте type=feature.
- Нумеруйте позиции с 1 до 50 в порядке появления результатов. Для результатов Яндекса и Google позиция считается среди органических карточек.
- Сохраняйте строки с колонками: engine, city, query, position, url, title, snippet, fetched_at (дата/время), proxy_id.
- Запускайте сбор по городам последовательно. Для каждого города перебирайте все запросы. Между запросами делайте задержку 3–8 секунд, между городами 10–20 секунд.
- Сохраните данные в data/raw/serp_results.csv. Дублируйте ежечасно копию с префиксом даты в папку резервных копий.
⚠️ Внимание: Некоторые поисковые системы не разрешают автоматизированный сбор. Рассмотрите официальный API (например, Google Custom Search API) или специализированные сервисы. Если все же парсите HTML, делайте это бережно и минимально, только для аналитических целей, соблюдая лимиты.
Совет: Разносите парсинг на раннее утро или поздний вечер, когда нагрузка ниже. Случайные паузы и чередование User-Agent снижают вероятность капчи.
✅ Проверка: В итоговом CSV должны быть записи по каждому городу и запросу, по 50 результатов на сочетание. Поля заполнены, URL корректны, позиции идут по порядку.
Проблемы и решения: если попадаете на капчу, увеличьте паузы, сократите одновременные запросы, используйте ротацию IP не чаще, чем раз в 2–5 минут. Если HTML-структура изменилась, обновите селекторы и ускорьте ручную проверку на 2–3 запросах.
Шаг 6: Очистка, нормализация и извлечение доменов
Цель этапа
Подготовить даные к анализу: убрать мусор, нормализовать URL, выделить домены, исключить нерелевантные элементы.
Пошаговая инструкция
- Загрузите CSV в pandas (скрипт scripts/clean_results.py). Проверьте наличие пустых title/snippet и при необходимости восстановите из альтернативных узлов HTML.
- Отфильтруйте дубликаты строк по (engine, city, query, url). Оставьте первую встречу.
- Исключите внутренние ссылки поисковиков, редиректы на кэш, ссылки на карты или новости, если они не нужны. Добавьте флаг type=organic для чистых органических результатов.
- Нормализуйте URL: удалите якоря, приведите схему к https, уберите параметры трекинга (utm_*, gclid и т.п.). Сохраните очищенный URL в отдельной колонке clean_url.
- С помощью tldextract получите домен второго уровня и зону. Сохраните в колонку root_domain, например “site.ru”.
- Сохраните очищенный файл в data/clean/serp_results_clean.csv.
Совет: Сразу добавьте колонку is_local_feature для результатов типа карты/справочника/маркетплейса, чтобы в анализе быстро отделять их от обычных страниц.
✅ Проверка: Число строк уменьшилось из-за удаления дублей и мусора, домены выделены корректно, нет служебных ссылок. Вы можете посчитать уникальные root_domain по городу и запросу.
Проблемы и решения: если слишком много результатов помечены как мусор, проверьте фильтры и уточните правила. Иногда полезно оставить крупные агрегаторы ради полноты картины.
Шаг 7: Кластеризация собранной семантики по интенту
Цель этапа
Разбить ключевые фразы на группы по интентам и тематическим кластерам, чтобы понимать, какой тип контента и страницы нужны для регионального продвижения.
Пошаговая инструкция
- Сформируйте список уникальных запросов из данных парсинга: возьмите колонку query и удалите дубликаты. Сохраните в data/clean/unique_queries.csv.
- Откройте Key Collector на Windows и создайте новый проект: Файл → Новый проект. Укажите имя проекта, например “Regional SERP Competitors”.
- Импортируйте список запросов: меню Импорт → Из файла → выберите unique_queries.csv. Убедитесь, что кодировка UTF-8.
- Создайте группы по темам. В Key Collector используйте инструмент кластеризации по морфологии или по общим словам. Начните с умеренных порогов схожести (например, 3 общих терминов), затем вручную поправьте группы.
- Пометьте каждую группу по интенту: информационный, коммерческий, навигационный. Для этого можно создать пользовательское поле. Примеры: информационный — “как выбрать”, “что такое”; коммерческий — “цена”, “купить”, “заказать”; навигационный — “бренд”, “официальный сайт”.
- Экспортируйте результат в CSV с колонками: query, cluster, intent. Сохраните в data/clean/queries_clustered.csv.
Совет: Если нет Key Collector, сделайте простую эвристику в pandas: создайте список токенов для каждого интента и классифицируйте запрос по наличию этих слов. Потом вручную проверьте спорные случаи.
✅ Проверка: Каждый запрос имеет кластер и интент. Большинство коммерческих запросов сгруппированы логично, информационные отделены от транзакционных.
Проблемы и решения: если группы получаются слишком широкими, снизьте пороги схожести. Если слишком узкими, повысьте пороги или объединяйте вручную. В сложных темах полезен гибридный подход: автоматическая первичная кластеризация + ручная доводка.
Шаг 8: Объединяем данные и готовим аналитические срезы
Цель этапа
Соединить SERP-результаты с кластеризацией, рассчитать полезные метрики для сравнительного анализа по регионам и конкурирующим доменам.
Пошаговая инструкция
- Загрузите data/clean/serp_results_clean.csv и data/clean/queries_clustered.csv в pandas (скрипт scripts/analyze_regions.py).
- Сделайте merge по колонке query, чтобы каждый результат получил cluster и intent.
- Добавьте вычисление позиции домена: для каждого сочетания city + query создайте ранжирование. Это уже есть в position, убедитесь в корректности.
- Посчитайте долю доменов по кластерам: группировка по city, cluster, root_domain, метрика средняя позиция и доля в топ-10.
- Добавьте флаг топ-10: position ≤ 10. Считайте покрытие домена в топ-10 по кластерам и по интентам.
- Сохраните промежуточные таблицы в data/clean/analytics_*.csv: например, coverage_by_city_domain.csv, top10_share_by_intent.csv.
Совет: В отчете удобно показывать «тепловые карты» покрытия: города по горизонтали, домены по вертикали, цвет — доля запросов в топ-10. Это выявляет сильных игроков по регионам.
✅ Проверка: Таблицы создаются без ошибок, в них понятные цифры: у локальных игроков выше доля топ-10 в своем городе, у федеральных — стабильная доля во многих городах.
Проблемы и решения: если в данных мало попаданий в топ-50, проверьте корректность парсинга и фильтров. Расширьте список запросов или увеличьте результат до 100, если это допустимо и безопасно.
Шаг 9: Анализ различий выдачи по регионам и локализации запросов
Цель этапа
Определить, какие запросы локализованы, какие нет, и как это влияет на стратегию SEO в разных городах. Выявить кластеры и домены с сильной локальностью.
Пошаговая инструкция
- Для каждого запроса соберите множества доменов в топ-10 по городам. Посчитайте пересечение между городами (например, Москва vs Санкт-Петербург). Метрика: Jaccard = |пересечение| / |объединение|.
- Постройте сводную таблицу Jaccard по всем парам городов. Низкие значения указывают на сильную региональную зависимость выдачи.
- Определите локализованные запросы: те, у которых средний Jaccard по всем парам городов ниже порога (например, 0.3). Для нелокализованных — порог выше (например, 0.6).
- Сравните интенты: обычно коммерческие запросы чаще локализованы, чем информационные. Проверьте это по средним значениям Jaccard внутри каждого интента.
- Выявите «уникальных» конкурентов по городу: домены, которые появляются в топ-10 только в одном городе. Подготовьте список для локальных ссылок и партнерств.
- Сформируйте отчет: 1) Топ локализованных запросов, 2) Топ нелокализованных запросов, 3) Домены уникальные для города, 4) Домены, стабильно сильные в нескольких городах.
- Сохраните отчет в reports/regional_differences.csv и сделайте текстовое резюме с рекомендациями.
Совет: Добавьте метрику «стабильность позиции» для домена: среднее и стандартное отклонение позиции по городам. Это поможет понять, где домен сильнее.
✅ Проверка: В отчетах видно, что часть запросов заметно различается между городами, а часть почти не меняется. Вы можете назвать по крайней мере 5 локализованных и 5 нелокализованных запросов из вашей выборки.
Проблемы и решения: если разница минимальна, возможно, тема мало зависит от региона или выборка слишком узкая. Добавьте запросы с локальным интентом (“рядом”, “доставка сегодня”, “в моем городе”) и повторите анализ.
Проверка результата
Чек-лист: 1) У вас есть рабочие мобильные прокси для 10+ городов, гео проверено. 2) Парсер собирает топ-50 по каждому городу и запросу, CSV не пустые. 3) Очистка и нормализация выполнены, домены извлечены. 4) Кластеризация по интентам завершена, каждому запросу присвоен intent. 5) Отчеты по различиям между городами сформированы. 6) В отчете есть списки локализованных и нелокализованных запросов. 7) Есть рекомендации по региональному SEO на основе данных.
Как протестировать: 1) Сравните несколько запросов вручную в браузере через соответствующий прокси. 2) Сверьте 5–10 строк CSV с реальными результатами. 3) Проверьте, что топ-10 по городам действительно различается там, где ожидаете.
Показатели успешного выполнения: покрытие данных не ниже 80% от планового количества сочетаний город × запрос; минимальное число ошибок сети; понятные, воспроизводимые отчеты.
Типичные ошибки и решения
- Проблема: капча и блокировки. Причина: высокая частота запросов, однотипные заголовки, отсутствие пауз. Решение: увеличьте задержки, уменьшите параллелизм, ротуйте IP реже, меняйте User-Agent, рассматривайте официальные API.
- Проблема: некорректная геолокация. Причина: прокси с неустойчивым гео или кэш. Решение: проверьте гео через Яндекс.Интернетометр, смените IP, возьмите другого оператора или город.
- Проблема: мусор в данных и дубликаты. Причина: неочищенные URL, рекламные блоки. Решение: добавьте фильтры по доменам, нормализуйте URL, сохраняйте только органику.
- Проблема: нестабильные селекторы HTML. Причина: изменения в структуре SERP. Решение: используйте более общие паттерны, проверяйте парсер на 2–3 запросах, обновляйте селекторы.
- Проблема: слишком узкие кластеры. Причина: высокий порог схожести. Решение: снизьте порог, объедините близкие кластеры вручную, проверьте токенизацию.
- Проблема: слабая различимость регионов. Причина: неправильный выбор запросов. Решение: добавьте локальные интенты и проверяйте Jaccard по парам городов.
- Проблема: перегрузка прокси. Причина: слишком много запросов подряд. Решение: распределите по времени, используйте дополнительные прокси, добавьте очереди и паузы.
Дополнительные возможности
Продвинутые настройки: 1) Кэширование ответов HTML по ключу (engine, city, query) для экономии запросов. 2) Хранение данных в SQLite или PostgreSQL с индексами по city, query, domain. 3) Логирование ошибок в отдельные файлы в logs с метками времени. 4) Добавление headless браузера (например, с помощью Selenium) только для проблемных запросов, где без JS не собирается сниппет. 5) Использование официальных API: Google Custom Search API, Яндекс.API (если доступны релевантные эндпоинты). Это снизит риски и повысит стабильность.
Оптимизация: 1) Рандомизация задержек и User-Agent. 2) Умное повторение: повторяйте только неуспешные запросы. 3) Выделение «тяжелых» запросов в отдельную очередь и обработка позже. 4) Еженедельный или ежемесячный запуск для мониторинга динамики.
Что еще можно сделать: 1) Подсчет Rank-Biased Overlap между городами для более тонкой оценки схожести выдачи. 2) Автоматическая генерация рекомендаций: какие страницы полезно создать для конкретного города. 3) Использование морфологического анализатора для русского языка для улучшенной кластеризации. 4) Подготовка дашборда (например, в Power BI) для визуализации покрытия доменов и интентов по городам.
Совет: Включите «черный список» доменов, которые всегда следует исключать из анализа (например, нецелевые сервисы), но храните копию сырых данных, чтобы при необходимости восстановить.
FAQ
Вопрос 1: Можно ли обойтись без мобильных прокси? Ответ: Да, если есть официальные API с параметрами региона или вы используете городские центры данных. Но мобильные прокси часто лучше отражают реальную локальную выдачу.
Вопрос 2: Как уменьшить вероятность капчи? Ответ: Увеличьте задержки, снизьте параллелизм, чередуйте User-Agent, используйте ротацию IP не слишком часто, и по возможности используйте официальные API.
Вопрос 3: Как понять, что запрос локализован? Ответ: Если состав доменов в топ-10 сильно меняется между городами (низкий Jaccard), а также в выдаче часто присутствуют локальные каталоги и карты, запрос локализован.
Вопрос 4: Что делать, если структуры HTML у Google и Яндекс меняются? Ответ: Держите парсер модульным, добавьте авто-тесты на 2–3 эталонных запроса. При изменении обновляйте только модуль парсинга.
Вопрос 5: Как правильно метить интенты? Ответ: Комбинируйте автоматические эвристики (списки слов-подсказок) с ручной проверкой спорных случаев. Интенты уточняйте по данным конверсий.
Вопрос 6: Что если в городе мало данных? Ответ: Расширьте список запросов, добавьте LSI-лексему и долгие хвосты, запустите в другое время суток, используйте альтернативные источники семантики.
Вопрос 7: Как учитывать агрегаторы и маркетплейсы? Ответ: Не удаляйте их полностью. Отмечайте как отдельный тип и анализируйте влияние на вашу нишу. Это конкуренты за трафик.
Вопрос 8: Можно ли совместить данные Google и Яндекс? Ответ: Да. В отчетах держите метку engine. Сравнивайте их раздельно и вместе, чтобы увидеть кросс-поисковую устойчивость доменов.
Вопрос 9: Как часто обновлять данные? Ответ: Раз в 2–4 недели для динамичных ниш, раз в 1–2 месяца для стабильных. Храните версии отчетов для отслеживания трендов.
Вопрос 10: Какие метрики самые полезные? Ответ: Доля топ-10 по доменам и кластерам, средняя позиция, стабильность позиции, Jaccard между городами, покрытие интентов.
Заключение
Резюме выполненных действий: вы подготовили прокси по городам, проверили гео, настроили Python-окружение, собрали топ-50 результатов в Google и Яндексе по выбранным запросам и регионам, очистили и нормализовали данные, кластеризовали семантику по интентам и провели анализ различий выдачи между городами. В результате у вас есть практически применимый отчет, который показывает, по каким запросам конкуренты сильны в каждом регионе и какие запросы локализованы.
Что делать дальше: 1) Создавайте и оптимизируйте локальные посадочные страницы под локализованные кластеры с коммерческим интентом. 2) Усиливайте E-E-A-T сигналами в городах, где позиция нестабильна. 3) Настройте регулярный сбор данных и мониторинг изменений. 4) Адаптируйте контент под информацию, востребованную в конкретных городах.
Куда развиваться: 1) Интеграция с CRM для оценки конверсий по регионам. 2) Добавление поведенческих сигналов и локальных ссылок. 3) Расширение числа городов и тематики запросов. 4) Автоматизация отчетности и визуализация в BI-инструментах.
Совет: Документируйте каждый этап и сохраняйте конфиги. Тогда ваш конвейер можно будет легко масштабировать на новые города и ниши.
Совет: Держите шаблон отчета и чек-лист запуска. Это экономит 30–40% времени при повторных итерациях.
